There is not a lot of information on this vocoder available online, so I have attempted to translate the journal article explaining ASELP from Mandarin Chinese to English. I have translated this with Google translate, some common sense, and some knowledge of radio, but if you think of a better translation for any sentence then let me know and I'll edit it if I agree with you.
Some things didn't translate very well and I have left them to allow readers to interpret the correct meaning, if possible.
If you know Mandarin and English and could help improve the translation then please leave a comment or contact me.
The original document in Mandarin Chinese can be viewed here.
Techniques of vocoder in digital trunking
CUI Huijuan, JI Zhe, HE Honghua, XU Jingde, CHANG Liang, ZHAO Haijun. Department of E.E. of Tsinghua University, Beijing, 100084, China, cuihuijuan@mail.tsinghua.edu.cn.
Abstract: The algorithm of ASELP vocoder at 2.4kb/s, 1.2kb/s for Digital Trunking System is presented in this paper. Vocoders are weak in naturalness, robustness and the high resources consumption of computing and storage resources that means high cost and power. These interferences are obstructions of its application in Digital Mobile Radio. In this ASELP vocoder, the proper excitation signal, simple quantizer and a post-processing are adopted, a trade off at the bit-rate between the vocoder and the FEC is applied. Take the advantages of these algorithms, this 2.4kb/s, 1.2kb/s ASELP vocoder is just perfect for a digital radio. It has been well used in Digital Trunking Systems.
Key words: ASELP: Advanced Sinusoidal Excitation Linear Prediction; Vocoder; Parameters Coding. Digital Radio; Digital Trunking.
1. Introduction.
Because of their strong advantages, digital walkie-talkies are gradually replacing analog walkie-talkies to become a major force in professional mobile communications.
Mobile communications can be divided into public mobile communications and professional mobile communications. Professional mobile communications systems are designed for business sectors such as railways, aviation, EMS, police and public security. Cell phones require the same walkie-talkie-like network so that they can be used in areas without coverage. Systems are required to be robust. This is currently beyond the capabilities of public cellular systems such as GSM and CDMA.
China's professional mobile communications technology system at this stage is divided into four levels to meet the needs of different user groups:
1) 400MHz public radio.
2) 150 MHz and 400MHz professional FM.
3) 900MHz decentralized [?] (无中心自) trunking communication systems.
4) 350MHz and 800MHz digital trunking communication systems.
On September 13, 2007 the Ministry of Information Industry issued official document (2007) 81 regarding "Radio Frequency Technical Requirements for Digital two way radio Systems Equipment" (for Trial Implementation) , marking the start of development of China's digital walkie-talkies.
In digital walkie-talkies, narrow band efficient speech coding is used instead of the original analog voice. Most currently use 2.4kbps vocoder technology.
Motorola, Kenwood, Icom and other companies in the digital two way radio industry use the United States DVSI’s AMBE 3000 2.45kbps vocoder. In April 2009, the dPMR MoU decided to adopt the AMBE 3000 2.45 kbps vocoder from the U.S. DVSI Company as the standard dPMR vocoder.
In light of this information, we responded to Chairman Jintao's call to "Grasp the rare opportunity of information technology improvements, rapid development of new materials, science and technology and claim the independent intellectual property rights of the core technologies of manufacturing and information industry to enhance the competitiveness of China’s industries" and we developed the ASELP vocoder with independent intellectual property rights in response to the requirements of professional mobile communication equipment.
2. ASELP vocoder.
The SELP vocoder is based on Tsinghua University’s linear prediction techniques using the sinusoidal excitation algorithm completed in the year 2000, with independent intellectual property rights.
In order to meet the needs of professional mobile communication systems such as digital trunking, we have made adaptive improvements to the aspects of excitation, quantization and post-processing, and improved performance to give the Advanced Sinusoidal Excitation Linear Prediction (ASELP) Vocoder.
In order to adapt to various topographies and achieve communications in all conditions, we use the source, channel variable parameter encoding strategy. ASELP vocoder has a flexible coding rate, so is the perfect use of this coding scheme. Figure 1 is the ASELP vocoder encoder block diagram.
2.1 ASELP encoder overview
2.1.1 ASELP vocoder parameters
Speech is a non-stationary signal with short-term (about 20ms) stability. As a result, the method of the frame division processing can be used to extract the speech model parameters in one frame (about 160 samples).
See Figure 1, the use of linear prediction techniques, coding extraction parameters are:
1) Represents the 10th order prediction coefficient (LSF) of speech spectral envelope;
2) Prediction of redundancy (Excitation);
3) Pitch of the vibration frequency of the vocal cords (Pitch);
4) Whether the sound is voiced or unvoiced;
5) Energy (Gain);
As with DMR, dPMR and other international standards’ sub-frame length, ASELP vocoder frame length is 20ms (160 samples/frame).
In the encoder, 160 speech samples per frame are processed: 1) First, accurately analyse and estimate the speech model parameters as described above; 2) Then, in accordance with the required coding rate, the parameters can be compressed to achieve high efficiency of quantization, coding; 3) Finally, the encoded stream multiplexed, which gives the output bit stream.
2.1.2 Variable rate ASELP vocoder implementation
ASELP vocoder has a frame length of 20ms. Parameter analysis and voice reconstruction use 20ms frames for the complete computing unit. In order to realize a vocoder with a lower code rate, ASELP uses a super frame mechanism to form a superframe with 2 frames, 3 frames, or more respectively. A superframe is used as an arithmetic unit for vector quantization to achieve a lower coding rate.
Vector quantization uses a large amount of computing, storage resources at the cost of access to efficient quantification. Application requires a compromise between performance and resources.
2.2 Coding parameter analysis algorithm selection
The vocoder application of a variety of parameters, a variety of analysis, synthesis algorithm, you can use different ways to achieve.
Our first consideration for applying parameters and analysis algorithms is high robustness. For example, the prediction coefficients are expressed in mathematically equivalent line-spectral frequency (LSF), the gain is extracted from the original speech signal, rather than from the predicted redundant signal, and so on. These improvements lead to a slight decrease in MOS (mean opinion score), but improve the vocoder robustness. In particular, the harsh howling of synthesized speech caused by bit errors or dropped packets is eliminated. This is especially important for wireless mobile communications.
 |
| Fig 1. The architecture of ASELP encoder. |
2.3 Quantization strategy for LSF parameters
2.3.1 Low complexity LSF parameter quantization
In this paper, the ASELP 2.4kbps vocoder uses the algorithm of globally optimal scalar quantization for the quantization of the prediction parameter LSF which occupies more than 50% of the coding rate. Designing an N-level quantizer, that is, selecting the reconstruction level and threshold, meets the minimum quantization distortion requirement.
 |
| Equation 1. |
Using the dynamic programming algorithm, the entire quantization interval of LSF is obtained, and the quantization level and the level of each layer are minimized, so that the quantization distortion D can be minimized.
Compared with vector quantization, scalar quantization saves resources:
1) The computation is reduced by about 36%.
2) The amount of memory is only 0.035 that of vector quantization.
With the same reconstructed speech quality, the scalar quantization is increased by about 15% compared with vector quantization.
2.3.2 LSF parameter low bit rate quantization
In order to further reduce the encoding rate, and considering the limited resources, a superframe is adopted for the LSF parameters, and multi-level vector quantization achieves a high quality 2 kbps vocoder.
2.4 ASELP vocoder decoding side
Figure 2 is ASELP vocoder decoder block diagram.
 |
| Figure 2. The architecture of ASELP decoder. |
1) First, the code stream framing processing;
2) Then decode, de-quantize, reconstruct speech parameters;
3) According to the statistical characteristics, the verification parameters are reasonable. And then the parameters of post-processing, remove the channel transmission error;
4) Finally, the reconstructed excitation signal is used to excite the linear prediction synthesis filter to obtain synthesized speech.
2.5 ASELP sinusoidal excitation mechanism
The voice signal is divided into vocal vibration (voiced) and no vibration (unvoiced):
1) Voiced: more information;
2) Unvoiced: Less information.
The statistical characteristics of speech signals show that in voiced speech segments, voiced speech accounts for about 65%. In the ASELP vocoder, a sinusoidal excitation algorithm is used for 65% of informative voiced segments.
From the human vocal mechanism analysis for voiced sounds, its frequency is called the pitch. As shown in Eq. (3), using the fundamental frequency ω of the vocal cords and its kth harmonic as excitation signals of voiced sounds gives a good representation of the original speech.
Voiced excitation:
 |
| Equation 2. |
 |
| Equation 3. |
 |
| Equations 4 and 5. |
 |
| Equation 6. |
2.4 kbps ASELP higher than MELPe: 7.685%;
1.2 kbps ASELP is higher than MELPe: 6.919%;
This proves that ASELP's algorithm is better.
2.6 ASELP Vocoder resource requirements
On the Tl DSP TMS320C55x hardware platform, ASELP 2.4 kbps vocoder required resources are as follows:
1) The amount of computation (code + decode) is about: 2.5MIPs;
2) Storage capacity:
- Program: 13k words;
- Memory: 10k words.
2.7 ASELP vocoder hardware implementation
Figure 3 shows the vocoder hardware module that has been completed. It compresses the input analog voice signal into the required encoding rate and outputs the compressed bit stream via SPI, UART or I2C interface. At the same time, it can decode the input compressed bit stream and reconstruct the analog voice signal output.
 |
| Figure 3. The hardware of ASELP vocoder. |
Module Size: 25.4mm X 25. 4 mm X 3.2 mm.
The module consumes about 10 mw or so. Speech coding algorithms implemented on the module:
1) ASELP voice encoder, encoding rate: 0.3 kbps, 0.6 kbps, 1.2 kbps, 2.4 kbps, 4.8 kbps, etc.
2) 8 kbps ITU-T G.729;
3) 16 kbps CVSD;
4) 64 kbps PCM;
5) Etc.
3 ASELP vocoder test results
3.1 Reconstruction of voice quality testing methods
This paper uses the ITU-T P.862 Objective MOS test method. The specific operation is the original voice, rebuild the voice input to this program, you can output objective MOS points. But the statement length is less than 4 MB.
3.2 Tsinghua University ASELP and the United States DVSI AMBE + 2 comparison
Table 1 compares Tsinghua University ASELP 2.4 kbps vocoder with the U.S. AMBE + 2.45 kbps vocoder from DVSI.
Table 1. Comparison of vocoder between ASELP and AMBE+2
Test sample
|
Vocoder
|
Bitrate
|
MOS
|
MIX1.wav
|
AMBE+2
|
2.45 kbps
|
3.237
|
MIX1.wav
|
ASELP
|
2.4 kbps
|
3.364
|
Conclusion: ASELP is superior to AMBE+2.
3.3 Tsinghua University ASELP compared with the US government standard MELPe
Table 2 shows the comparison between Tsinghua University ASELP 2.4 kbps vocoder and the U.S. government standard MELPe 2.4 kbps vocoder.
Table 2. Comparison of vocoder between ASELP and MELPe.
Test sample
|
MELPe
|
ASELP
|
MIX1.pcm
|
2.983
|
3.294
|
MIX2.pcm
|
2.982
|
3.225
|
MIX3.pcm
|
2.988
|
3.278
|
MIX4.pcm
|
2.993
|
3.250
|
Average
|
2.9865
|
3.26175
|
The ASELP's MOS is better than the MELPe vocoder.
3.4 ASELP compared to TETRA ACELP 4.567 kbps
Table 3 shows the Tsinghua University ASELP 2.4kbps vocoder, compared with the European digital trunking TETRA speech encoder ACELP at a coding rate of 4.567 kbps.
Table 3. Comparison of vocoders ASELP and TETRA ACELP.
Test sample
|
ACELP
|
ASELP
|
MIX1.pcm
|
3.225
|
3.294
|
MIX2.pcm
|
3.163
|
3.225
|
MIX3.pcm
|
3.183
|
3.278
|
MIX4.pcm
|
3.180
|
3.250
|
Average
|
3.195
|
3.26175
|
4. Practical applications
Tsinghua University ASELP has been widely used at a variety of encoding rates in various communications at home and abroad.
4.1 Applied to Daxinganling forest defence digital trunking system
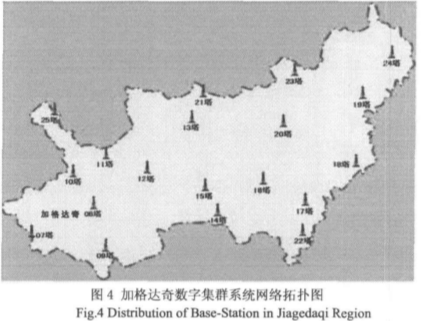 |
| Figure 4. Distribution of base stations in the Jiagedaqi Region. |
Figure 4 shows the network topology of the ADUCS (Advanced Digital UHF communication System) digital trunking system in the region of Jiagedaqi. The Daxinganling Jiagedaqi Forestry Bureau ADUCS trunking system is equipped with 13 base stations covering an area of about 180,000 square km. A single base station covers an average radius of about 2 km. ADUCS is configured with ASELP 2.4kbps and 1.2 kbps: two different encoding rates, depending on the actual system needs to determine the vocoder encoding rate.
4.2 Conclusion
The ITU-T P862 PESQ program tests, home and user measurements and practical applications show that Tsinghua University ASELP vocoder is suitable for digital trunking systems.
References
[1] Li Jinliang, Proposal for Formulating Digital Professional Mobile Communication Standard in China, Mobile Communications, May 2008.
[2] T.E. Tremain, The Government Standard Linear Predictive Coding Algorithm: LPC-10, Speech technology, pp.40-49. April 1982.
[3] Jiang Hao, Cui Huijuan, and Tang Kun, “Sinusoidal Excitation LPC vocoder” Chinese Journal of Electronics, Vol.7, No.3, pp.296-300.
[4] Draft FIPS publication on MELP, “Analog to digital Conversion of voice by 2,400 Bit/second Mixed excitation linear prediction”, Federal information processing standards publication. June 12 1997.








In response to your comment: "Not sure why you have it as ASELP when its actually ACELP. VSELP has the "S" and ACELP has the "C". And I love ACELP audio quality over VSELP. My days working with on Moto equipment that used VSELP showed that quality was ok. ACELP is leaps and bounds over that on TETRA. Then there is poor ole AMBE and IMBE...time to put those to rest"
ReplyDeleteHuh? ACELP and ASELP are completely different vocoders. ASELP = Advanced Sinusoidal Excitation Linear Prediction. ACELP = Algebraic code-excited linear prediction. ACELP was made by VoiceAge Corporation, ASELP was made by a Chinese university.
Any Decoder available for ASELP like the one in md380 tools, I need software to decode it
ReplyDelete